概要:阿里巴巴智能计算研究院的研究人员开发了一种名为“EMO”的新人工智能系统,可以根据单张肖像照片生成说话或唱歌的视频,表现出惊人的逼真性。该系统利用了一种称为扩散模型的AI技术,绕过了中间的3D模型或面部标志,直接将音频波形转换为视频帧。这一创新代表了在音频驱动的说唱头像视频生成领域的重大进步,挑战了多年来AI研究人员的技术水平。尽管这项技术展示了个性化视频内容合成的未来,但同时也引发了人们对潜在滥用的道德担忧,尤其是未经同意的冒充他人或传播虚假信息。研究人员表示,他们计划探索检测合成视频的方法。
![]()
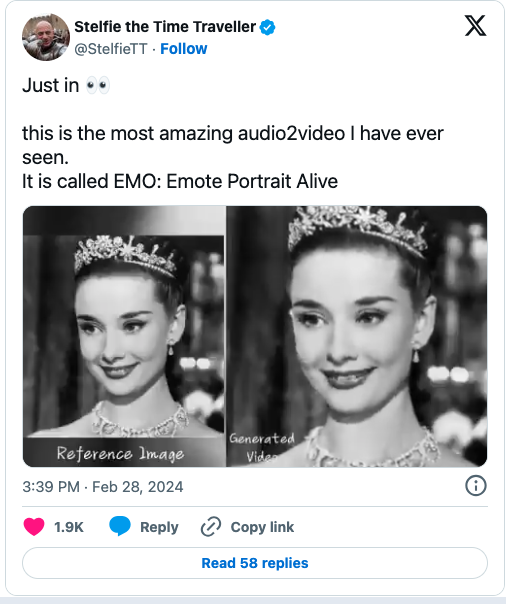
阿里巴巴研究人员开发了一种名为“EMO”的新人工智能系统,可以根据单张肖像照片生成逼真的说话或唱歌视频。该系统绕过了传统技术中常见的中间步骤,直接将音频转换为视频,从而捕捉到了更丰富的面部表情和个性化的特征。
据阿里巴巴智能计算研究院的研究人员介绍,这一系统利用了一种称为扩散模型的AI技术,该技术已被证明在生成逼真的合成图像方面具有出色的能力。研究人员使用了来自演讲、电影、电视节目和唱歌表演等各种视频素材,对EMO进行了训练。与以往依赖3D面部模型或混合形状来近似面部动作的方法不同,EMO直接将音频波形转换为视频帧,从而捕捉到了与自然语音相关的微妙运动和身份特定的特点。
在论文中描述的实验中,研究人员发现,EMO在衡量视频质量、身份保留和表现力等指标上明显优于现有的最先进方法。他们还进行了用户研究,发现EMO生成的视频比其他系统产生的视频更自然、更富表现力。
除了会话视频外,EMO还可以根据声音同步生成适当的口型和引人入胜的面部表情,以唱歌肖像。根据输入音频的长度,该系统支持生成任意时长的视频。
尽管这项技术展示了个性化视频内容合成的未来,但同时也引发了人们对潜在滥用的道德担忧,尤其是未经同意的冒充他人或传播虚假信息。研究人员表示,他们计划探索检测合成视频的方法。
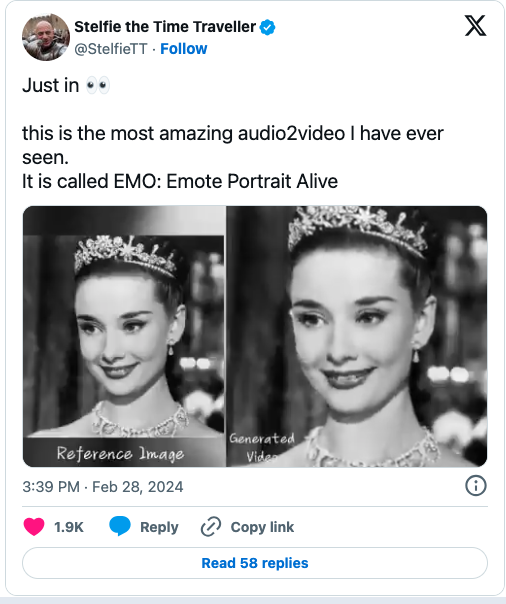
EMO系统代表了人工智能在视频合成领域的巨大进步。通过直接将音频转换为视频,它能够捕捉到更多的面部细节和个性化特征,生成的视频更加逼真。然而,这项技术也带来了道德和隐私方面的担忧,因为它可能被滥用来冒充他人或传播虚假信息。研究人员的计划探索检测合成视频的方法将对解决这些问题起到关键作用。