
概要: 微软的Orca-Math AI取得了令人瞩目的成就,表现优于大小是其10倍的模型。这一成就为学生和STEM研究人员带来了喜悦,尤其是对于那些数学困难的人来说,这将极大地提升他们的能力。文章将深入探讨Orca-Math的出色表现,以及背后的技术和方法。
微软的Orca-Math AI刚刚发布,但已经展现出了令人惊讶的性能。作为Mistral 7B模型的一个变体,它在解决数学问题方面表现出色,而且体积相对较小,易于训练和推断运行。这是微软Orca团队致力于提升小型大型语言模型(LLMs)能力的一部分。[https://www.microsoft.com/en-us/research/blog/orca-math-demonstrating-the-potential-of-slms-with-model-specialization/]
Arindam Mitra,微软研究院的高级研究员兼Orca AI团队负责人,发表了一篇关于Orca-Math的帖子,宣布了这一重大进展。他指出,Orca-Math在解决数学单词问题方面表现优异,而且模型体积相对较小。这一成就是通过一系列创新技术和方法实现的。
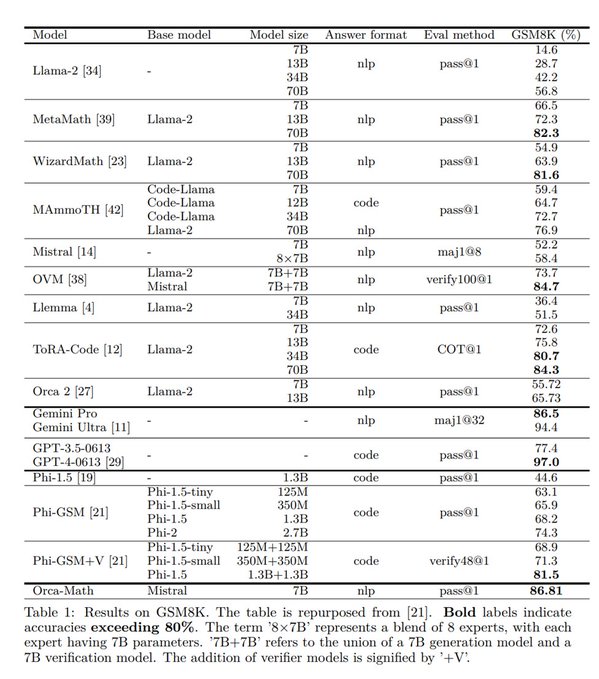
Orca-Math模型的突破表现在于它的小尺寸。尽管只有70亿个参数,但在GSM8K基准测试中,它的表现几乎与参数更多的模型相媲美,如OpenAI的Gemini Ultra和OpenAI的GPT-4。与MetaMath(70B)和Llemma(34B)等更大参数模型相比,它表现得更加突出。
Orca团队是如何实现这一突破的呢?Mitral透露说,他们利用了一种新的数据集,其中包含由“专门的代理人共同制作”的20万个数学单词问题。这些问题是通过收集现有的开源数据集中的36,217个“样本数学单词问题”生成的,然后通过OpenAI的GPT-4来获取答案,并利用这些答案来训练新的Mistral 7B变体,最终形成了Orca-Math。
与此同时,Orca团队还利用了一种“建议和编辑”代理人来开发更复杂的问题,用于训练AI。这种合成数据集的应用进一步证明了机器生成数据对增强LLMs的智能和能力是有用的,减轻了“模型崩溃”的担忧。
此外,微软的Orca团队还在Hugging Face上发布了他们的合成AI生成的20万个数学单词问题数据集,允许“每个人都能探索、构建和创新”。这为初创公司和企业提供了巨大的便利,可以利用这一数据集进行相关研究和创新。