
概要:Gretel发布了世界上最大的开源文本到SQL数据集,为企业释放人工智能潜力提供了动力。该数据集不仅扩大了AI模型训练的范围,还为全球企业带来了新的可能性。
![]()
在合成数据行业中,Gretel 「https://gretel.ai/#main」 一直是开拓者。该公司在上周四宣布发布了世界上最大的开源文本到SQL数据集,这一举措将加速AI模型的训练,并为全球企业开辟新的可能性。
这个数据集拥有超过100,000个精心制作的合成文本到SQL样本,覆盖了100个不同行业。现在,这个数据集已经在Hugging Face平台上以Apache 2.0许可证的形式开放。Gretel此举旨在为开发人员提供必要的工具,使他们能够创建强大的AI模型,这些模型可以理解自然语言查询并生成SQL查询,从而弥合了业务用户和复杂数据源之间的差距。
“获得高质量的训练数据是利用生成式人工智能的最大障碍之一。” Gretel的首席科学家Yev Meyer在接受VentureBeat采访时强调说:“高质量的合成数据可以填补这一空白。最近在大型语言模型(LLMs)和人工智能领域最值得注意的一次转变之一是对数据质量的重新关注。”
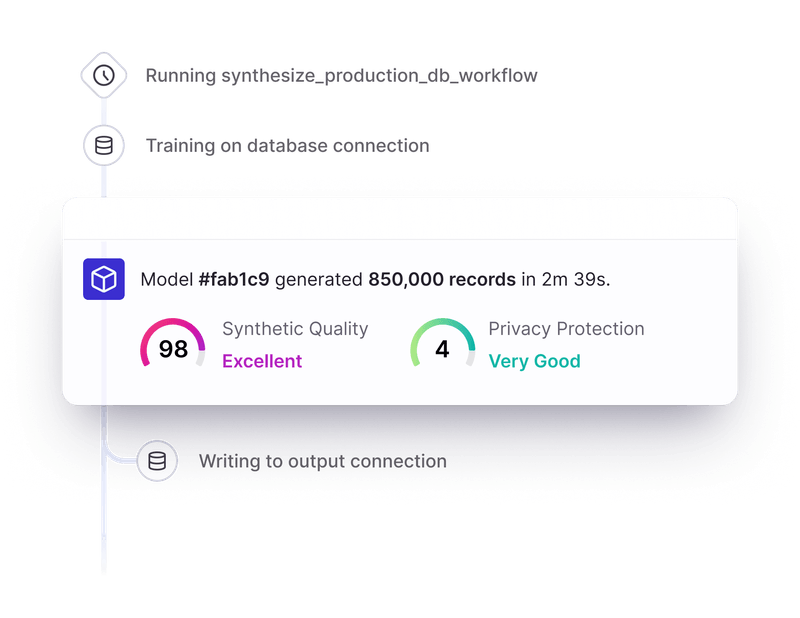
Gretel的划时代数据集是使用Gretel Navigator生成的,这是一款目前处于公开预览阶段的复合型AI系统。“我们的开源文本到SQL数据集是由Gretel Navigator生成的,这是我们的复合型AI系统,它集成了基于代理的执行、多个专有模型(包括定制的表格化大型语言模型)和隐私增强技术,能够根据需要从头开始生成高质量的合成数据。” Meyer解释道。
这一发布的影响是深远的,因为各行各业的企业都在努力解决访问和利用复杂数据库、数据仓库和数据湖中蕴藏的丰富数据的挑战。Gretel的数据集不仅提供了解决方案,还包括一个解释字段,为终端用户提供了SQL代码的通俗解释,使其更容易理解并从输出中提取价值。
Gretel对数据质量的严格验证和广泛行业应用
Gretel对数据质量的承诺体现在其细致的验证过程中。“我们生成的每个数据集都要经过质量评估。质量基准测试是我们工作的核心。” Meyer表示。该公司的文本到SQL数据集在使用独立服务和LLM作为评判技术进行评估时,在SQL标准符合度、正确性以及遵循指令方面始终优于其他数据集。
Gretel的合成文本到SQL数据集在各种评分标准下均优于b-mc2/sql-create-context数据集,包括符合SQL标准(+54.6%)、SQL正确性(+34.5%)和遵循指令(+8.5%),由独立LLM作为评判技术评估得出。
Gretel数据集的潜在应用非常广泛,涵盖了从金融和医疗保健到政府等各行各业。金融分析师现在可以提出关于公司业绩的问题,并即时从数据库中获取答案,而医疗保健提供者可以简化对多次试验的临床试验数据的分析。政府领导人也可以利用该数据集为公民提供便利访问公共记录数据库,如许可证、财产所有权和许可证。
平衡数据隐私与可访问性
随着企业越来越认识到以数据为中心的人工智能的重要性,Gretel生成大量高质量合成数据的能力使其成为该行业的关键参与者。“Gretel的解决方案是为企业规模构建的,以便客户在从头开始创建数据或编辑和增强现有数据时满足其数据需求。” Meyer告诉VentureBeat。
Gretel在隐私方面的承诺同样令人印象深刻,采用了差分隐私等前沿技术,确保敏感信息得到保护,同时使模型能够从数据中学习。在数据安全至关重要的行业中,Gretel在平衡准确性和隐私方面的承诺使其脱颖而出。
Gretel发布文本到SQL数据集标志着该公司加速采用以数据为中心的人工智能、赋予企业释放其数据潜力的使命迈出了重要的一步。凭借其对质量、隐私和可访问性的关注,Gretel已经做好了在合成数据革命中发挥引领作用的准备。
随着人工智能领域以惊人的速度发展,Gretel对开源社区的划时代贡献证明了其推动创新、使高质量训练数据民主化的承诺。这一发布的涟漪效应可能会在各行各业产生影响,因为企业利用人工智能获取竞争优势,在日益数据驱动的世界中推动增长。