微软今日宣布发布Phi-3,这是一款强大的30亿参数语言模型,提供先进的推理能力,类似于更大型模型,但成本显著更低。由微软研究团队开发,新模型将在公司的Azure AI平台上提供,使企业能够利用最先进的自然语言处理和推理技术。
![]()
"重要的是,我们能够拥有一个非常微小的模型,具备与更大型模型相匹敌的能力,包括接近GPT-3.5级别的性能,"微软生成AI副总裁Sébastien Bubeck告诉VentureBeat。"这才是最重要的。这不一定是我们所期待的进步类型。我想没有人知道你需要多大规模的模型才能获得接近GPT-3.5级别的能力。"
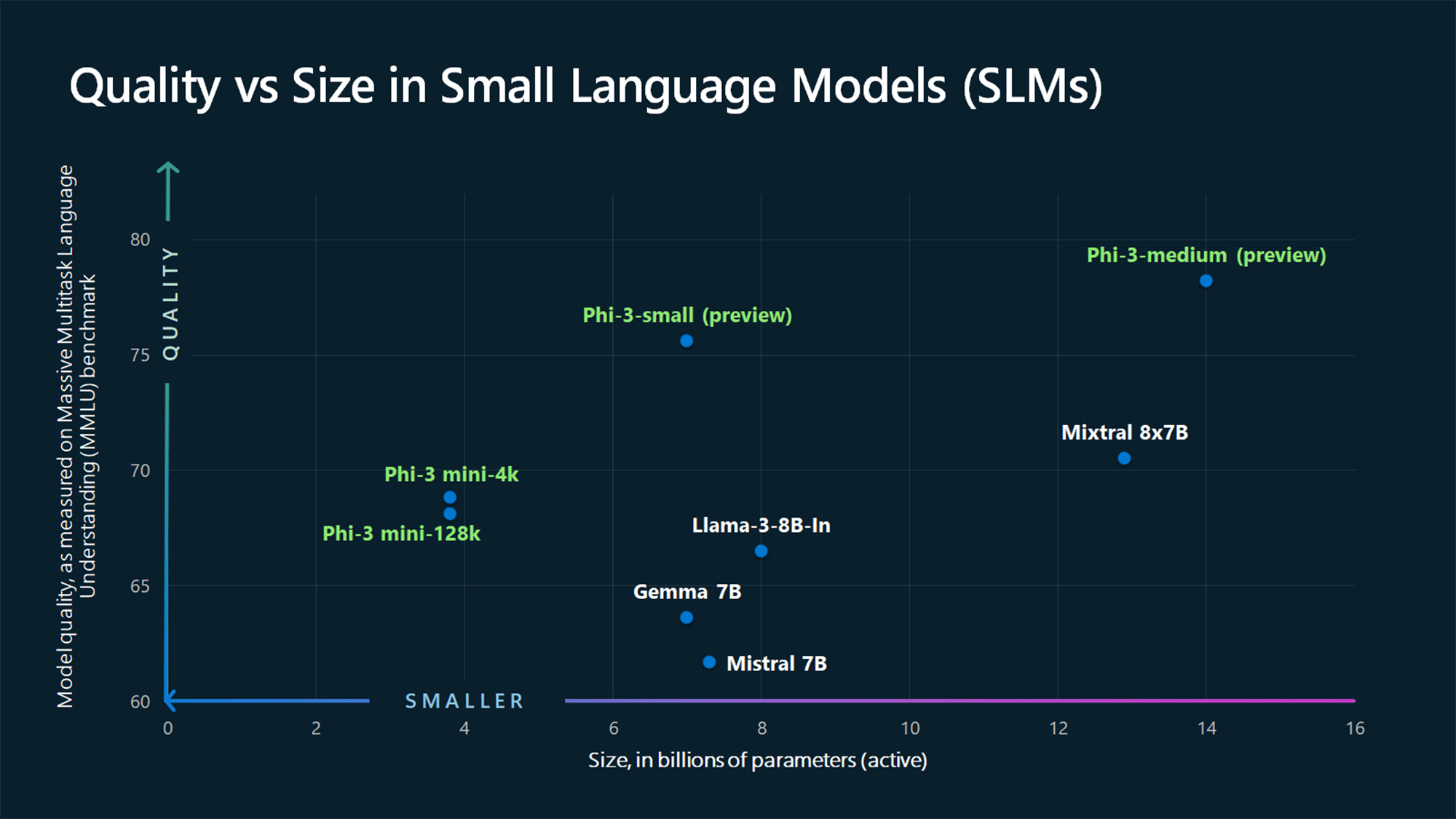
微软探索紧凑型语言模型极限的努力取得了最新的成就。从一年前的以编码为导向的Phi-1开始,经过Phi-1.5和Phi-2的进展,Phi系列展示了在编码、常识推理和一般自然语言基准方面的出色性能,模型规模仅为10亿至20亿参数。
为企业提供经济高效的AI
"随着客户看到可能性是什么,每个客户都在奔走相告,‘好吧,现在我需要做一些有趣的事情,’"Azure AI平台企业副总裁Eric Boyd告诉VentureBeat。"在Azure上,我们正在帮助这些客户构建他们所需的生成式AI应用程序…我们将始终拥有最强大的模型,真正推动前沿,展示可能性的边界。但在此过程中,我们也将在每个价格点上拥有最佳模型。"
微软从一开始就考虑到了其责任AI原则,开发了Phi-3。模型的训练数据经过了毒性和偏见的筛选,并在发布前采取了额外的安全措施。这使得企业,特别是那些处于受监管行业的企业,能够自信地利用Phi-3的能力。
从技术角度来看,Phi-3运行在为NVIDIA GPU优化的ONNX Runtime上,并且可以以分布式方式部署在多个GPU或多台机器上以优化吞吐量。该模型的架构利用了高效的注意机制和优化的数值精度,以实现相对较少参数的高性能。
"美妙的地方在于,现在你有了一个在小型模型中的基础层,你可以引入你的数据,对这个通用模型进行微调,在狭窄的垂直领域获得惊人的性能,"Bubeck解释道。"即使选择了一个狭窄的领域,你也需要通用智能很好,即使在这个垂直领域。"
微软推出Phi-3并计划将其集成到Azure AI平台中,标志着为各种规模的企业提供大型语言模型能力的重要一步。随着越来越多的公司试图使AI实现业务化,并释放其非结构化数据的价值,像Phi-3这样的定制模型将是实现这一愿景的关键所在。